This statement is used to handle duplicate entries efficiently by combining insert and update operations in a single query. It behaves like a normal INSERT until a duplicate key is encountered.
- Inserts new rows when no duplicate key exists.
- Updates existing rows on duplicate key conflict.
- Works only with PRIMARY KEY or UNIQUE constraints.
- Prevents errors and ensures smooth data handling.
Syntax:
INSERT INTO table_name (column1, column2, ...)
VALUES (value1, value2, ...)
ON DUPLICATE KEY UPDATE
column1 = value1,
column2 = value2;The ON DUPLICATE KEY UPDATE clause specifies the columns to update when a duplicate key is detected.
Working with INSERT ON DUPLICATE KEY UPDATE
It allows inserting new records while automatically updating existing ones when a duplicate key occurs. It ensures efficient data handling by combining insert and update operations in a single query.
1. Create Table
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
);2. Insert Initial Data
INSERT INTO employees (name)
VALUES ('Alice'), ('Bob'), ('Charlie');3. View Data
SELECT id, name FROM employees;Output:
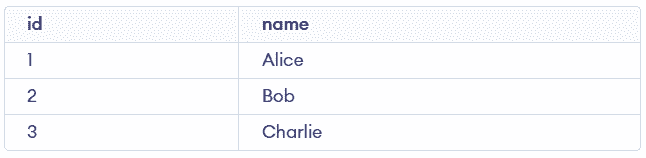
4. Insert Without Duplicate
INSERT INTO employees (name)
VALUES ('David')
ON DUPLICATE KEY UPDATE name = 'David';Since there is no duplicate key, MySQL inserts a new row.
5. View Updated Data
SELECT id, name FROM employees;Output:
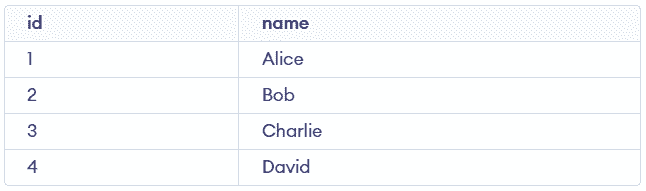
6. Insert With Duplicate Key
INSERT INTO employees (id, name)
VALUES (4, 'Eve')
ON DUPLICATE KEY UPDATE name = 'Eve';Since id = 4 already exists, MySQL updates the existing row instead of inserting a new one.
Output:
2 row(s) affected7. Final Data
SELECT id, name FROM employees;Output:
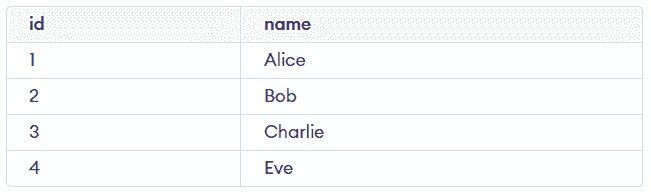
Best Practices
Follow these guidelines to safely and effectively use INSERT ON DUPLICATE KEY UPDATE.
- Use Proper Constraints: Ensure PRIMARY KEY or UNIQUE indexes are correctly defined.
- Update Selectively: Modify only required columns to prevent data loss.
- Validate Data: Avoid blindly overwriting existing values.
- Test Bulk Operations: Be cautious when using with multiple row inserts.
